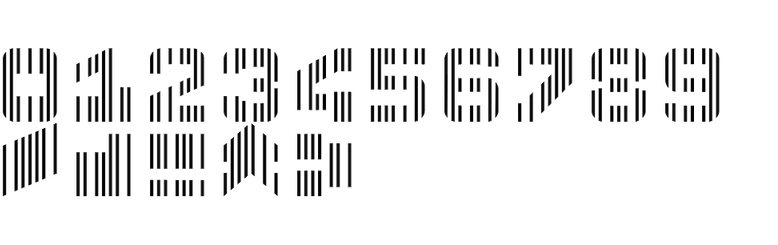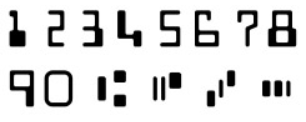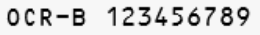Supported languages
Optical character recognition can recognise a wide range of different languages or different types of text.
Refer to Enum Language in the API REFERENCE for more details on each.
Afaan Oromo |
Dutch |
Interlingua |
Moldovan |
Slovak |
Afrikaans |
English (American) |
Irish Gaelic |
Mongolian (Cyrillic) |
Slovenian |
Albanian |
English (British) |
Italian |
Nahuatl |
Somali |
Arabic*/** |
Esperanto |
Japanese* |
Nigerian Pidgin |
Sotho |
Asturian |
Estonian |
Javanese |
No language, Latin alphabet |
Spanish |
Aymara |
Faroese |
Kapampangan |
Norwegian |
Sundanese |
Azeri (latin) |
Fijian |
Kazakh (Cyrillic) |
Norwegian Bokmål |
Swahili |
Balinese |
Finnish |
Kikongo |
Norwegian Nynorsk |
Swedish |
Banking fonts (cf. API REF) |
French |
Kinyarwanda |
Numeric |
Tagalog |
Basque |
Frisian |
Korean* |
Nyanja |
Tahitian |
Belarusian |
Friulian |
Kurdish |
Occitan |
Tatar (Latin) |
Bemba |
Galician |
Latin |
Papiamento |
Tetum |
Bikol |
Ganda |
Latvian |
Polish |
Thai* |
Bislama |
German |
Lithuanian |
Portuguese |
Tok pisin |
Bosnian (Cyrillic) |
German (Switzerland) |
Luba |
Quechua |
Tongan |
Bosnian (Latin) |
Greek |
Luxembourgish |
Rhaeto-Romance |
Traditional chinese* |
Brazilian Portuguese |
Greenlandic |
Macedonian |
Romanian |
Tswana |
Breton |
Haitian Creole |
Madurese |
Rundi |
Turkish |
Bulgarian |
Hani |
Malagasy |
Russian |
Ukrainian |
Catalan |
Hebrew* |
Malay |
Samoan |
Uzbek (Latin) |
Cebuano |
Hiligaynon |
Maltese |
Sardinian |
Vietnamese* |
Chamorro |
Hungarian |
Manx |
Scottish Gaelic |
Waray |
Corsican |
Icelandic |
Maori |
Serbian |
Welsh |
Croatian |
Ido |
Mayan |
Serbian latin |
Wolof |
Czech |
Ilocano |
Mexican Spanish |
Shona |
Xhosa |
Danish |
Indonesian |
Minangkabau |
Simplified chinese* |
Zapotec |
|
OCR Extensions required
|
| Type | Specifications | Example |
|---|---|---|
CMC7 |
MICR (Magnetic ink character recognition code). |
|
E13b Optical |
MICR (Magnetic ink character recognition code). |
|
OCR-A1 |
OCR-A1 Alphanumeric |
|
OCR-B1 |
OCR-B1 Alphanumeric |
|